Regresión lineal en Python
Pronóstico de la demanda: Mínimos cuadrados
Quienes nos adentramos desde hace varios años en el mundo de la estimación de la demanda, hemos considerado a la regresión lineal, o al método de los mínimos cuadrados, como un modelo de pronóstico, no mucho más que eso.
Sabemos que nos permite hallar el valor esperado de una variable aleatoria a cuando b toma un valor específico. Entendemos que este método implica un supuesto de linealidad cuando la demanda presenta un comportamiento creciente o decreciente.
Es común que hagamos uso de una hoja de cálculo sobre la cual aplicamos las fórmulas de regresión, tal como lo detallamos en este artículo de introducción: regresión lineal.
Sin embargo, con los avances computacionales, con el incremento de la capacidad de procesamiento de información, con el crecimiento de las herramientas utilizadas en la ciencia de datos; con la consideración de términos como inteligencia artificial, machine learning, y muchos conceptos relacionados; podemos definir a la regresión lineal en este contexto: La regresión lineal es una técnica paramétrica de Machine Learning. Es un algoritmo supervisado.
En esta oportunidad, y teniendo en cuenta lo que venimos mencionando; utilizaremos Python, y una librería para aprendizaje automático: scikit-learn, para abordar modelos de regresión lineal. Las ventajas de Python como lenguaje que nos permita integrar diversas aplicaciones, fuentes de información, y posibilidades de modelamiento de datos a gran escala, son muchas. Por esta razón dejaremos esta herramienta a disposición.
Ejemplo de aplicación de Regresión lineal mediante Python
La juguetería Gaby desea estimar mediante regresión lineal simple las ventas para el mes de Julio de su nuevo carrito infantil «Mate». La información del comportamiento de las ventas de todos sus almacenes de cadena se presenta en el siguiente tabulado:
| Mes | Periodo | Ventas |
| Enero | 1 | 7000 |
| Febrero | 2 | 9000 |
| Marzo | 3 | 5000 |
| Abril | 4 | 11000 |
| Mayo | 5 | 10000 |
| Junio | 6 | 13000 |
Importar librerías
Para llevar a cabo este ejercicio necesitaremos una serie de librerías, vamos a describir cada una de ellas:
- Numpy: Es el paquete fundamental para la computación en matrices con Python.
- Matplotlib: Es un paquete para crear gráficos en Python.
- Sklearn: Un conjunto de módulos de Python para el aprendizaje automático y la minería de datos.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
Desde la librería sklearn importaremos las clases liner_model y mean_squared_error para obtener la regresión lineal por mínimos cuadrados y para evaluar la calidad de a regresión.
Crear la data de entrada
De acuerdo a nuestro ejemplo, los periodos los almacenaremos en una lista contenida en la variable x. Así mismo, los datos de la demanda los almacenaremos en una lista contenida en la variable y.




Crearemos una lista (z) con los períodos que queremos pronosticar, en este caso, las ventas para el periodo 7.
x = [1,2,3,4,5,6]
y = [7000, 9000, 5000, 11000, 10000, 13000]
z = [7]
#Convertimos las listas de entrada en matrices
x = np.array(x)
y = np.array(y)
z = np.array(z)
#Graficamos los datos de entrada
plt.scatter(x,y,label='data', color='blue')
plt.title('Distribución entre meses y demanda');
Las listas con los datos de entrada los convertiremos en matrices para procesar posteriormente la información. El modelo de aprendizaje automático trabaja a partir de matrices.
Por último, graficaremos la data de entrada. El resultado parcial de nuestro programa será:
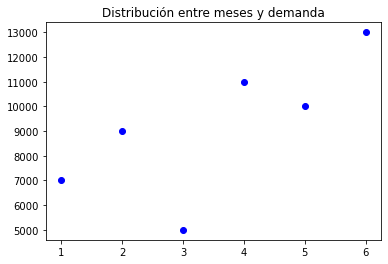
Entrenar el modelo de regresión lineal
Crearemos una instancia de la clase LinearRegression con el nombre de regresion_lineal. A continuación, utilizaremos el método fit el cual ajusta el modelo lineal de acuerdo a los datos de entrada (x, y).
regresion_lineal = linear_model.LinearRegression()
regresion_lineal.fit(x.reshape(-1,1), y)
# Imprimimos los parámetros que ha estimado la regresión lineal
print('\nParámetros del modelo de regresión')
print('b (Pendiente) = ' + str(regresion_lineal.coef_) + ', a (Punto de corte) = ' + str(regresion_lineal.intercept_))
Lo siguiente que haremos – y ya que el modelo de regresión se ha ajustado a los datos de entrada – será obtener los parámetros de regresión:
- coef_ = Valor de la pendiente.
- intercept_ = intersección de la línea con el eje.
Hemos añadido algo de formato a los parámetros que mostrará el desarrollo. Veamos:
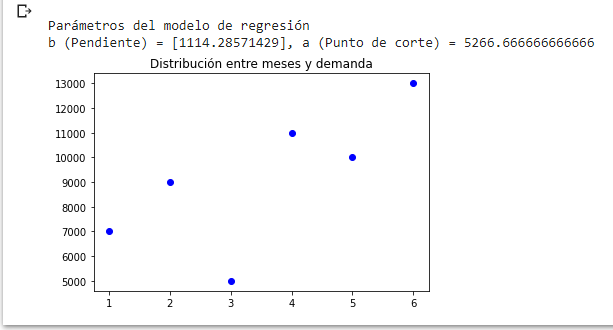
En este punto ya hemos obtenido a través del modelo entrenado, los parámetros de regresión del conjunto de datos.
Prediciendo datos a partir del modelo entrenado
Toda vez que el modelo ha obtenido los parámetros de regresión, podemos predecir datos utilizando el método predict.
En este caso, queremos pronosticar el valor de la demanda (y) para el periodo 7 (z).
pronostico = regresion_lineal.predict(z.reshape(-1,1))
print('\nPronósticos')
for i in range(len(z)):
print('Pronóstico para el periodo {0} = {1} '.format(z[i], pronostico[i]))
La matriz de las predicciones se almacenará en la variable pronostico. El método predict hará la tarea. Recordemos que los periodos a partir de los cuales queremos conocer la demanda se encuentran en la matriz z. Por ende, queremos predecir con base en los valores de z. Así:
pronostico = regresion_lineal.predict(z.reshape(-1,1))
Podríamos simplemente imprimir la variable pronostico, en cuyo caso obtendremos nuestras predicciones en forma de matriz. Sin embargo, hemos decidido utilizar un bucle que nos imprima línea por línea (útil en los casos en los cuales queramos ronostica más de un período). Veamos el resultado parcial de nuestro código:
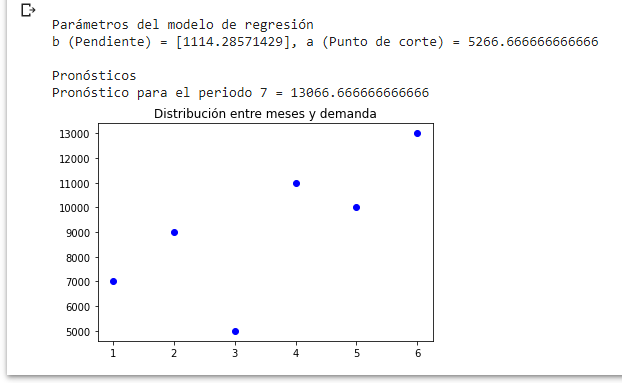
Podemos observar que la estimación de la regresión lineal del modelo que acabamos de entrenar para x = 7 es y = 13066,66. Puede contrastar este resultado con el obtenido mediante hojas de cálculo: regresión lineal.
Evaluando la calidad de la regresión
Para evaluar la calidad del modelo de regresión desarrollado utilizaremos el error cuadrático medio y el coeficiente de determinación R². Ambos datos podemos obtenerlos de una manera muy sencilla mediante la librería empleada. Veamos:
pronostico_entrenamiento = regresion_lineal.predict(x.reshape(-1,1))
mse = mean_squared_error(y_true = y, y_pred = pronostico_entrenamiento)
rmse = np.sqrt(mse)
print('\nEvaluación de calidad de la regresión')
print('Error Cuadrático Medio (MSE) = ' + str(mse))
print('Raíz del Error Cuadrático Medio (RMSE) = ' + str(rmse))
r2 = regresion_lineal.score(x.reshape(-1,1), y)
print('Coeficiente de Determinación R2 = ' + str(r2))
Para tratar de simplificar lo anterior, podemos decir que en la práctica lo necesario es calcular el pronóstico para los valores en x conocidos como valores de entrada; dicho en otras palabras, el pronóstico para los valores en x utilizados para entrenar el modelo. De esa manera el error cuadrático medio (método mean_squared_error) comparará el valor de los datos en y «reales» versus los valores en y «pronosticados» (Para los x conocidos – entrenamiento -).
Para hallar la raíz del error cuadrático básicamente usamos la función de Python sqrt que calcula la raíz cuadrada del argumento dado.
Para obtener el coeficiente R² utilizaremos el método score.
Imprimiremos los valores y obtendremos:
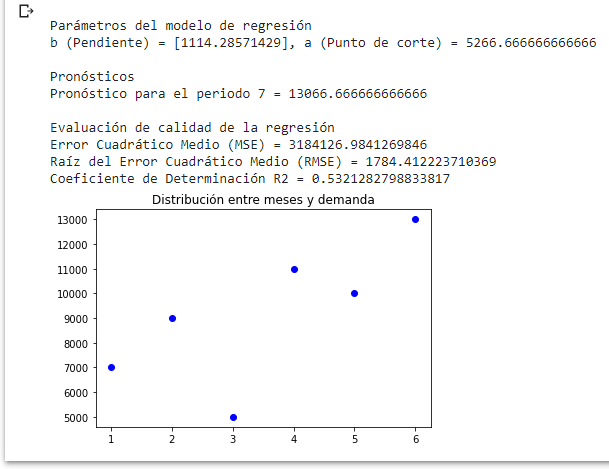
El coeficiente R² igual a 0,532 indica la existencia de una correlación pero nada fuerte.
Graficar la línea de la tendencia del modelo
Vamos a graficar la línea de la tendencia, para eso necesitamos los valores de entrada para x y la demanda pronosticada (dependiente). Utilizaremos plot de manera que la gráfica resultante sea una línea y dentro de los argumentos le daremos color rojo.
plt.plot(x,pronostico_entrenamiento,label='data', color='red')
plt.xlabel('Meses')
plt.ylabel('Demanda')
Además nombraremos los ejes del gráfico. Veamos:
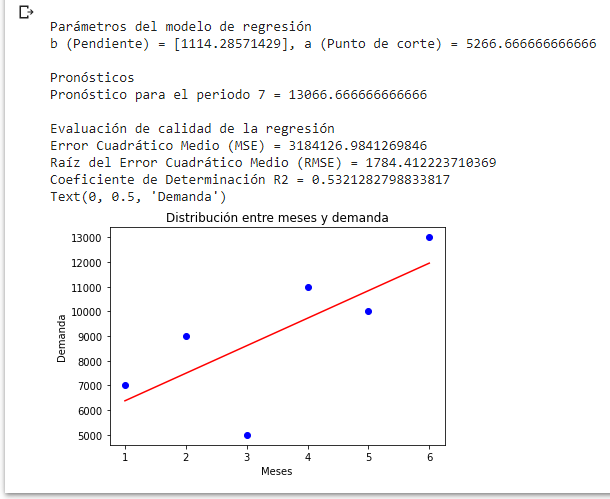
Hasta aquí hemos logrado entrenar un modelo de regresión lineal; logramos obtener la predicción con base en el modelo entrenado. Logramos graficar los datos de entrada y la línea de tendencia. Del mismo modo logramos evaluar la calidad de la regresión mediante un par de indicadores.
Veamos ahora una pequeña variación: queremos obtener predicciones para diversos periodos. Lo único que necesitaremos es modificar la lista de entrada z. En esta lista contenemos los periodos que queremos pronosticar. Veamos lo que pasa cuando z = [7, 8, 9, 10].
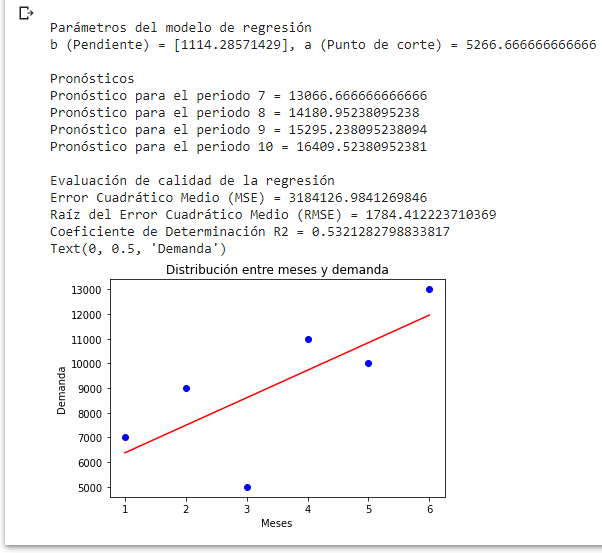
Aquí apreciamos la utilidad del bucle que implementamos para imprimir los pronósticos línea por línea.
A continuación, dejamos a disposición el código completo del modelo de regresión:
rojo.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
#Inputs
x = np.array([1,2,3,4,5,6]) #periodo de entrenamiento
y = np.array([7000, 9000, 5000, 11000, 10000, 13000])
z = np.array([7, 8, 9, 10, 11, 12]) #Periodos que deseo pronosticar
plt.scatter(x,y,label='data', color='blue')
plt.title('Distribución entre meses y demanda');
regresion_lineal = linear_model.LinearRegression()
regresion_lineal.fit(x.reshape(-1,1), y)
print('\nParámetros del modelo de regresión')
print('b (Pendiente) = ' + str(regresion_lineal.coef_) + ', a (Punto de corte) = ' + str(regresion_lineal.intercept_))
# vamos a predecir el periodo 7 (z = [7]
pronostico = regresion_lineal.predict(z.reshape(-1,1))
print('\nPronósticos')
for i in range(len(z)):
print('Pronóstico para el periodo {0} = {1} '.format(z[i], pronostico[i]))
pronostico_entrenamiento = regresion_lineal.predict(x.reshape(-1,1))
mse = mean_squared_error(y_true = y, y_pred = pronostico_entrenamiento)
rmse = np.sqrt(mse)
print('\nEvaluación de calidad de la regresión')
print('Error Cuadrático Medio (MSE) = ' + str(mse))
print('Raíz del Error Cuadrático Medio (RMSE) = ' + str(rmse))
r2 = regresion_lineal.score(x.reshape(-1,1), y)
print('Coeficiente de Determinación R2 = ' + str(r2))
plt.plot(x,pronostico_entrenamiento,label='data', color='red')
plt.xlabel('Meses')
plt.ylabel('Demanda')
¿Cómo ejecutar el modelo?
Alternativa 1, ejecución en nuestro equipo:
Lo primero que debemos considerar, en el caso de que queramos ejecutar este código en nuestro equipo, es que es preciso contar con la instalación de Python.
Ahora, lo recomendable es trabajar con algún editor de código práctico (IDE), por ejemplo: Sublime Text, o Spyder (Una herramienta más completa y por ende más robusta y pesada).
Alternativa 2, ejecución en un entorno virtual (Recomendado):
Podemos utilizar del mismo modo, un entorno virtual. En este caso recomendamos el uso de Colaboratory de Google, un entorno que cuenta con todas las herramientas necesarias para nuestros desarrollos. No tendremos que instalar nada en nuestro equipo, y aprovecharemos la potencia de las máquinas de Google.
Puedes ver y ejecutar el cuaderno de este módulo en nuestro Colaboratory: Regresión lineal en Python.